Paper - R-CNN 논문 리뷰
Paper Review를 작성해 보았다.
R-CNN Review
- R-CNN의 논문을 보면서 Two Stage와 One Stage에 대해 찾아보는 좋은 기회가 되었다.
1. Introduction
1) classification
2) Object Detection
3) Image Segmentation
4) Visual Relationship
CV(Computer Vision)은 위에 4가지로 분류가 된다.
- Classification : Single object에 대해서 object의 클래스를 분류하는 문제
- Classification + Localization : Single Obect에 대해서 Object의 위치를 Bounding Box로 찾고 (Localization) + 클래스를 분류하는 것(Classification)
- Object Detection : Multiple objects에서 각각의 object에 대해서 Classification + Localization을 수행하는 것
- Instance Segmentation : Object Detection과 유사하지만, 다른점은 object의 위치를 bounding box가 아닌 실제 edge로 찾는 것
1.1. 2-Stage-Detector
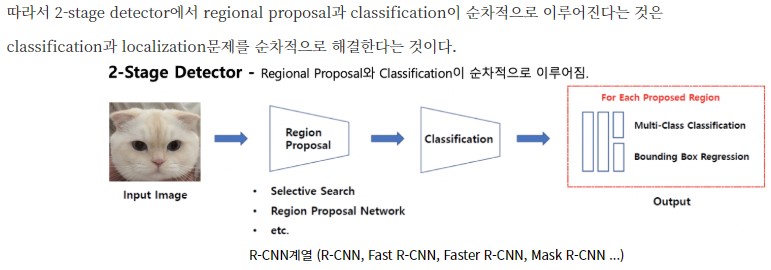
- R-CNN계열(R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN etc.)
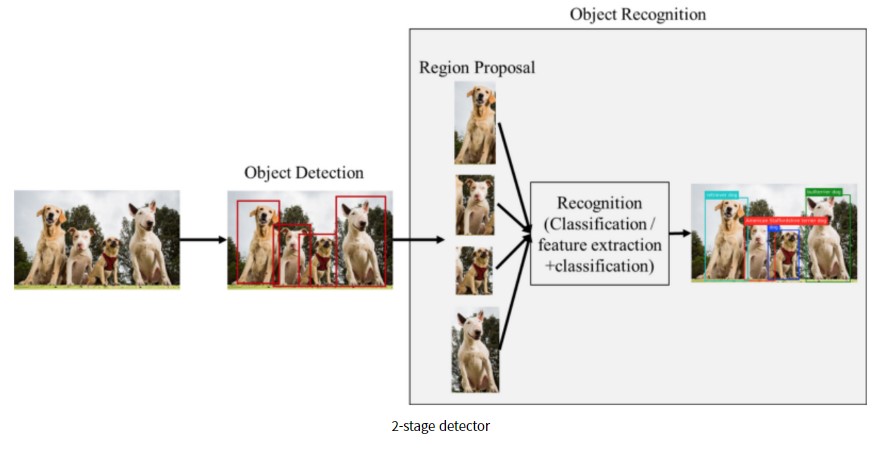
- 2-Stage Detector는 Region Proposal network등과 같은 알고리즘 및 네트워크를 통해 객체가 있을 영역(Region of Interest, RoI)을 추출해낸다. 이후 Classification과 Localization을 진행한다.
1.2. 1-Stage-Detector
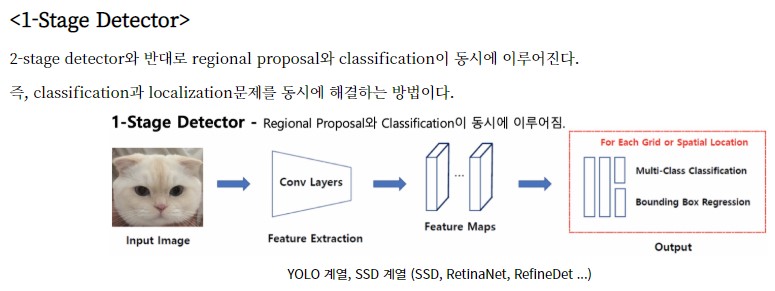
- YOLO, SSD계열(SSD, RetinaNet, RefineDet etc.)
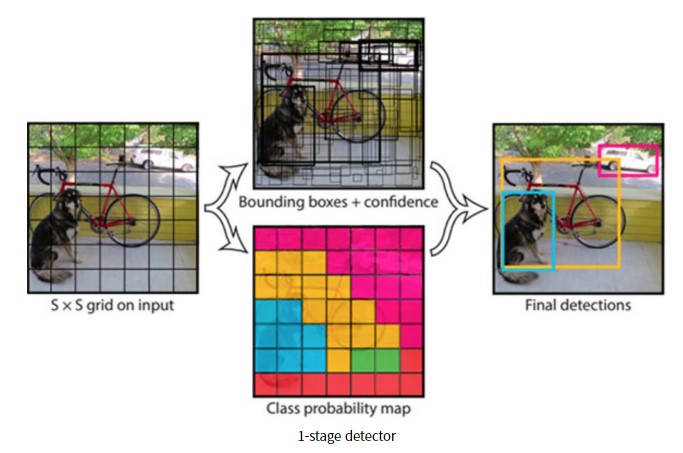
- 1-Stage Detector는 RoI를 추출하지 않고 전체 이미지에 대해 Convolution Network로 Classification과 Localization을 진행한다.
1.3. 2-Stage-Detector와 1-Stage-Detector의 장단점
- 2-Stage-Detector장점 & 단점
- 속도가 빠르지만 정확도가 떨어진다.
- 1-Stage-Detector장점 & 단점
- 정확도가 높지만 속도가 느리다.
2. R-CNN
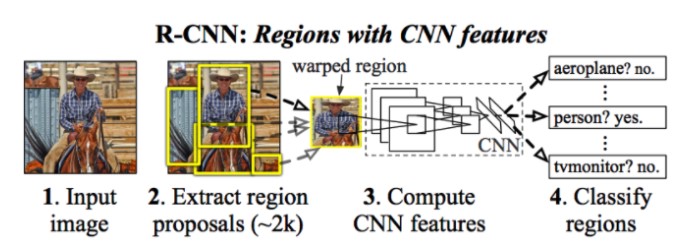
- R-CNN은 위에서 보았던, 2-Stage-Detector라고 볼 수 있다.
- R-CNN의 진행과정은 다음과 같다.
- 이미지 입력
- Selective search알고리즘을 사용하여 대략 2,000개의 regional proposal output추출 후 동일한 input size를 만들기 위해 warp해준다.(마지막 FC layer에서 input size는 고정이기 때문에 Convolution Layer에 대한 output size도 동일해야 해서 input size에서 부터 동일한 사이즈를 넣어주어야 한다.)
- 대략 2,000개의 warped image를 CNN모델에 투입
- 각각의 Convolution 결과를 기반으로 Classification(SVM)을 진행 후 결과 추출
2.1. Region Proposal
- Sliding window(이미지의 맨 위에서 부터 쭉 읽으면서 탐색)은 탐색이 너무 느리고 비효율적이여서 Selective search알고리즘을 사용하게 됨
Selective search
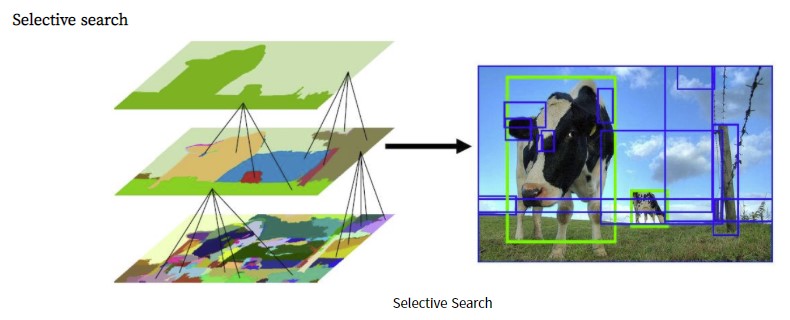
- Selective search의 진행과정
- 색상, 질감, 영역크기 등을 이용하여 Non-object-based segmentation수행
- Bottom-up 방식으로 small segmented areas들을 합쳐서 더 큰 segmented areas를 만듦
- 두번째를 반복을 통해 최종적으로 대략 2,000개의 region proposal을 생성
* 주의사항: CNN에 넣기 전에 같은 사이즈로 warp해주어야 한다.
2.2. CNN
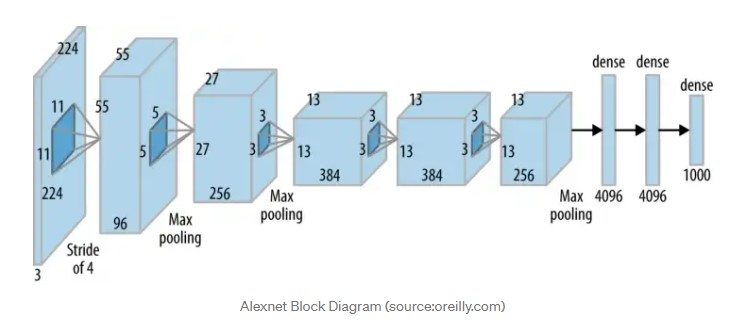
CNN은 AlexNet의 구조를 사용하며 Resion proposal로 부터 4096차원의 특징 벡터를 뽑아낸 후 고정된 길이의 특징 벡터를 만들어낸다.
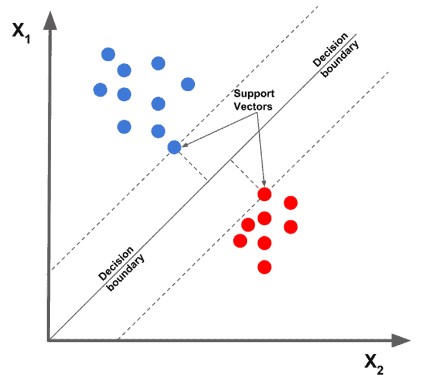
2.3. SVM
softmax보다 SVM이 좋은 성능을 보여 SVM을 사용하였다고 한다.
{kind=link}
- SVM은 CNN(AlexNet)으로 부터 추출된 각각의 특징 벡터들의 점수를 클래스별로 계산 후 객체인지 아닌지, 어떤 객체인지 등을 판별하는 역할을 하는 Classifier이다.
2-4). Bounding Box Regression
- Bounding Box Regression은 처음에 y로 줬던 레이블과, CNN을 통과해서 나온 Bounding Box, 이 두 가지의 차이를 구해서 차이를 줄이도록 조정하는 선형회귀 모델 절차
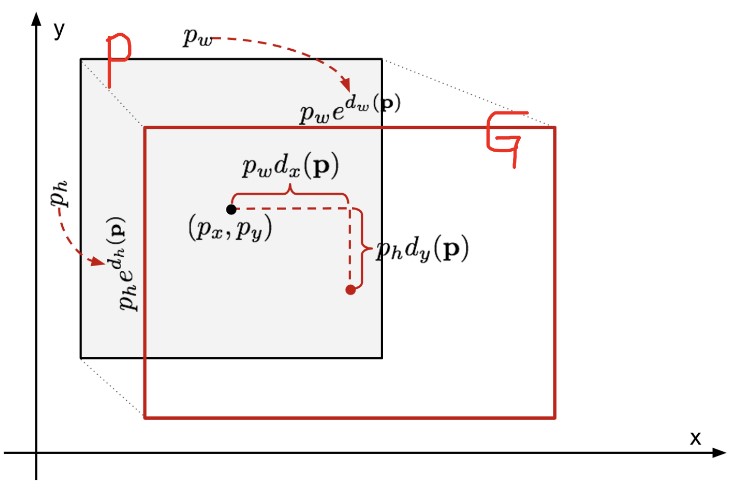
- 위 그림에서 P가 처음에 region proposal을 통해서 제안된 Bounding Box이고, G는 Ground Truth Bounding Box(정답 박스) 여기서 P를 정답 G에 맞추도록 transform 하는 것을 학습하는 것이 바로 Bounding Box Regression의 목표
3. 정리
- 이미지 하나의 임의의 영역들로 잘게 잘라서 merge 하고 warping 한 후,
- CNN의 input으로 통과하여 Feature vecture를 추출하고,
- 적용된 label들을 이용해 SVM 분류와 Bounding Box Regression을 수행해서 영역 위치까지 예측을 하게 되는 모델이 바로 R-CNN